What is it?
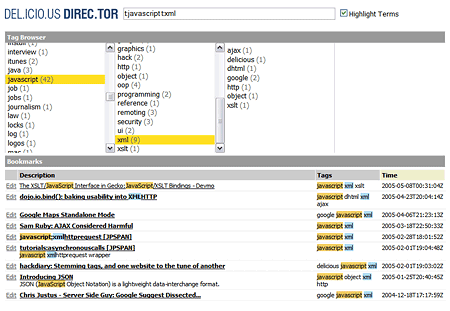
del.icio.us direc.tor is a prototype for an alternative web-based rich UI for del.icio.us. It leverages the XML and XSL services of modern browsers to deliver a responsive interface for managing user accounts with a large number of records.
The main features are:
- In-browser handling of del.icio.us bookmarks (tested up to 12,000 records)
- Find-as-you-type searching of all your bookmarks, with basic search operators
- Sort by description, tags, or timestamp
- Ad-hoc tag browser
Coverage of this feature around the web:
- del.icio.us on crack
—Lifehacker - ...yet another stunning remix
—Jon Udell - ...elegant alternate interface to your del.icio.us tags and bookmarks
—Jesse James Garrett - gorgeously designed Ajax-style browser for Del.icio.us
—waxy.org - Oh my god. del.icio.us direc.tor is my new best friend.
—Mulling It Over - Run. Don’t walk to try this out.
—Lisa McMillan - A lovely lovely shiny thing buried under quite a lot of brain-slide-offable verbiage
—plasticbag.org - ...this application will make you weep. Seriously.
—Gadgetopia
How do I use it?
Because of the restrictions on the browser, you'll need to load this using a Javascript bookmarklet. Follow these four steps to get started:
- Create a bookmarklet by bookmarking the following link:
- Go to api.del.icio.us
- Launch the bookmark you just created while you are still on the del.icio.us page
- Login to del.icio.us, if prompted
(Try the static demo if you don't have a del.icio.us account.) - Type in a search term or click a tag in the browser; click the column headings to sort
NOTE: This only works on Firefox and Internet Explorer. Safari won't work because it doesn't support XSLT via Javascript.
Supported operators
direc.tor supports the following operators:
t:<search_term> | Search only in tag field Ex: t:humor |
d:<search_term> | Search only in description field Ex: d:politics |
-<search_term> | Exclude results containing search term Ex: -microsoft |
Combining operators, like -t:nonsense, is currently not supported.
How does it work?
The idea behind a client-side web service broker (or intermediary, as Jon Udell calls it) is simple: assist a client in interpreting or processing information from a service, but letting the client do all the work (just like what "strategic management consultants" do). Unlike other web services like Amazon Light or Googlism that execute all of the program logic on the server side, a client-side broker sends all of the logic over as Javascript and has the browser do the work.
Other brokering services like the Google Maps hack are not entirely self-contained and require the broker host to proxy information between the main server and the client, thus doubling the amount of network traffic and degrading the overall performance. direc.tor eliminates the need for the broker host to proxy requests by instructing the client to directly communicate with the main server. This approach is very similar to the way Greasemonkey scripts are loaded, except that it is largely platform independent and does not require additional client-side extensions like Greasemonkey. However, the major pitfall to this approach is that users are required to manually create the bookmarklet.
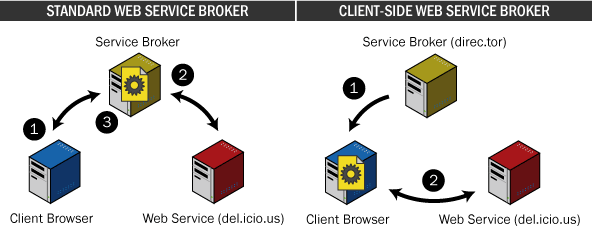
In a standard service, the Client Browser makes a request to the Service Broker (1), which in turn makes a request to the Web Service (2). The response from the Web Service is then transformed by the Service Broker, and presented to the Client Browser (3). In a client-side service, the Client Browser gets the entire service logic from the Service Broker (1), and then communicates directly with the Web Service (2).
Loading the service
This project uses the only reliable loophole for executing foreign Javascript code: the bookmarklet bootloader. It works by inserting a <script> element directly into the DOM, which is then immediately executed by the browser. The injected Javascript wipes the existing del.icio.us page and replaces the entire body with the direc.tor UI. At the same time, direc.tor makes an XmlHTTPRequest to http://del.icio.us/api/posts/all to get the XML listing of the user's bookmarks, which is persisted through the lifetime of the direc.tor page. Because del.icio.us uses the standard HTTP basic authentication, the browser will automatically ask for credentials if it has not been established yet. Since the client is communicating directly with del.icio.us, those credentials never pass through this site. For more information about this, and cross-site scripting concerns, see Creating a client-side web service broker.
Filtering and sorting the bookmarks
Performance is the primary concern — and often a severely limiting factor — when developing an in-browser application that handles large amounts of data. Filtering and sorting recordsets over 10,000 records though traditional Javascript objects is so sluggish that it simply is not a viable solution. del.icio.us direc.tor bypasses that limitation by leveraging the speed of the XML and XSL processors accessible via Javascript in modern browsers. Because these components are compiled binaries, their methods are orders of magnitude faster than an equivalent implementation in intepreted Javascript. del.icio.us direc.tor offloads all of the heavy lifting and a majority of the HTML generation to the XSLT processor to provide a responsive user interface. Since this is a rather lengthy discussion in and of itself, I have moved it to its own article: Using XSLT to filter and sort records in the browser.
Implementing the tag browser
Although it seems that the tag browser doesn't display a great deal of information, it too cannot be implemented with efficiency using straight Javascript. The main reason is that the tags and their relationship to the bookmarks can't be indexed in a way that allows fast retrieval. Brute force approaches work fine when the record count is around 1000 or so, but at 10,000 records the processing time becomes prohibitive. Again, I use the compiled XML resources to tackle the heavy lifting and allow direc.tor to handle large record sets. Another structure that is essential is an adjacency list, which allows for the fast, indexed retrieval of a tag and its related tags.
The major hurdle is not doing the initial retrieval of tags, but finding tags that have more than one other tag in common, i.e. "Show me all the tags that appear with the tag 'blog' and 'photo'." The brute force approach would cycle through all of the records, return those that contain the tag 'blog', cycle through that subset in search of 'photo', and then finally list and count all of the remaining tags that aren't 'blog' or 'photo'. Instead, direc.tor uses a single XPath query to pull out the subset of tags:
//posts/post[contains(string(@tag),'blog') and contains(string(@tag),'photo')]
Once that subset of nodes is returned by the XML engine, the tags from each node are inserted into a modified adjacency list, represented as a hashtable of hashtables in Javascript. The subset of nodes returned is almost always signifcantly smaller than the entire record set, making subsequent Javascript operations responsive enough for a decent user experience. The outer hashtable is keyed by tag name, such that every tag that exists in the current node set is represented. The inner hashtables store the related tags and the number of occurences.
 Example: This diagram represents a bookmark collection that has a total of 6 unique tags: blog, design, css, photo, cool, politics. The outer hashtable (left) uses each of those tags as its keys, while its values are hashtables that contain the key tag and any tag that is related. The values of those inner hashtables represent the total count of each tag and its occurence with the outer tag.
Example: This diagram represents a bookmark collection that has a total of 6 unique tags: blog, design, css, photo, cool, politics. The outer hashtable (left) uses each of those tags as its keys, while its values are hashtables that contain the key tag and any tag that is related. The values of those inner hashtables represent the total count of each tag and its occurence with the outer tag.
The hashtable's fast key-based retrieval makes it an ideal indexer for storing the tag counts, and fulfilling the tag requests from the user. Getting a list of tags is accomplished by enumerating over the hashtable keys, and getting the tag counts involves retrieving the values from the inner hashtables.
Highlighting the search terms
The search term highlighting is currently implemented using Javascript, by way of a generic search and replace method that wraps search terms with a <span> tag. The method then assigns one of the 6 CSS colors that are defined in the stylesheet. I'm sure that it could also be done in XSL, but I was unable to create out a template that would highlight multiple query terms that occur in a random order (if you have one, I'd love to see it). Because of Javascript performance limitations, single letter query terms are not highlighted. The highlighting takes place in the pipeline after the XSL transformation, but before the DOM node is actually brought online and painted in the browser (this is good general practice, as editing live DOM objects is horrifically slow.)
What else could this do?
There are probably hundreds of other features that would be cool to implement, so here are some that I would implement if I had more time:
- Bulk tag editing: Enable tag addition and removal from multiple bookmarks (which would then give me an excuse to implement the fancy fade anything technique).
- Labeling: Designate a tag as a special UI flag that mimics Gmail's "starred" functionality.
- Other operators: Add
OR,since:,related:, andinurl:operators. - Media detection: Expose media player controls for registered types, like MPG, MOV, WMV, etc.
- RSS import: Expand the input processor to parse RSS feeds, i.e. other people's tags.
- XML export: Allow download of an XML version of a current search, or all bookmarks.
- Link autopreview: Enable an Outlook-style bookmark preview pane.
- OS X Dashboard integration: Port direc.tor to a Dashboard widget.
The ultimate feature, though, would be to integrate some of this project directly into del.icio.us in order to eliminate the bootloading process altogether. I'm sure all you cats on delicious-discuss can come up with a collective feature list. I did this project to research different interface possibilities on other projects, so by all means, let me know if you're interested in helping make this a more mature service.
Thanks go to the DHTML grandmaster, Nick Mealy, and VMWare guru, John Zedlewski, for their help with this project.